
 2022-08-24
2022-08-24
High Availability in PostgreSQL on the example of EuroDB
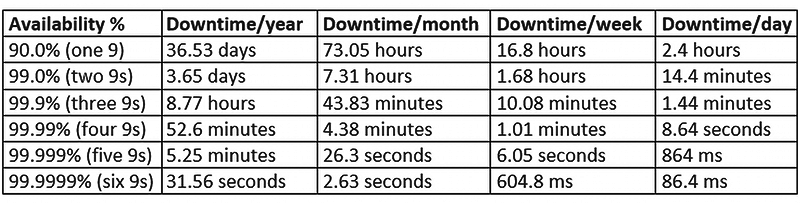
A standard High Availability system should be available 99.999% of the time – it can have 5 minutes and 15.6 seconds of downtime per year. Because of the number of nines, it is called “five nines.” However, there are “six nines” or “seven nines” systems. In this article, we will take a closer look at HA and discuss the types of high availability system architectures in PostgreSQL.
What is the meaning hidden behind the “High Availability” phrase? Why do so many services consider them to be the basis of the project and what does it mean for contemporary business? In the following article, we will take a closer look at this topic and present the benefits of using it.
Let’s start with the basics and the very definition of High Availability – in short HA. It is a system characterised by high availability, performance and reliability. It is most often used for critical tasks in the military, in air or city traffic management systems, as well as for monitoring the health in hospitals. The current technological capabilities push the boundaries of critical systems and it is thanks to this development that at any time we are able to order food, pick up a package, launch a cleaning robot or find answers to the questions that bother us. All this is available by following three main rules for the design of high-availability systems:
- elimination of single points of failure – i.e. elements of infrastructure, such as a server or a service, whose failure causes problems for the entire system
- creation of a redirection system – which in the event of failure of one of the elements of the system notifies another about taking over its tasks. Thanks to this, it is possible to continue the operation of the system
- detection of failures at their occurrence
The above rules mean that the average user may not even notice the failure.
Uptimes in HA systems
The high availability system should be available for 99.999% of the time. In other words, it can have 5 minutes and 15.6 seconds of downtime within a year. This time seems negligible, but in some cases, where human life is at stake, it may still be too high. To increase the distinction between HA systems based on their uptimes, a naming principle using nines was created.
For example, the standard HA system we discussed earlier, can be defined as “five nines”. However, we can imagine that there are systems of “six nines” or even “seven nines”, better by 10 or 100 times, respectively. The annual unavailability times for them are 31.56 or 3.16 seconds, respectively.
The term “nine fives” (55.5555555%) is also jokingly added as a contrast to “five nines” (99.999%) to deride the operation of a system that notoriously crashes and crates problems.
Advantages of using High Availability systems
Owning high availability systems brings a number of advantages, the most important of which are:
- elimination of system downtimes
- increase in data security
- saving money, time and nerves when repairing the entire system.
The high-availability systems are more and more frequently present, even in small and medium-sized enterprises, slowly becoming the standard. Thanks to this, companies prove their stability and credibility.
Types of High Availability System Architectures in PostgreSQL
High Availability also plays a key role for all types of databases, especially in the banking, online shopping and identification systems sectors (for example, airports). Such databases have many architectures for managing high availability systems. In Postgres, you can divide them into two main types: Primary-Standby and Primary-Primary.
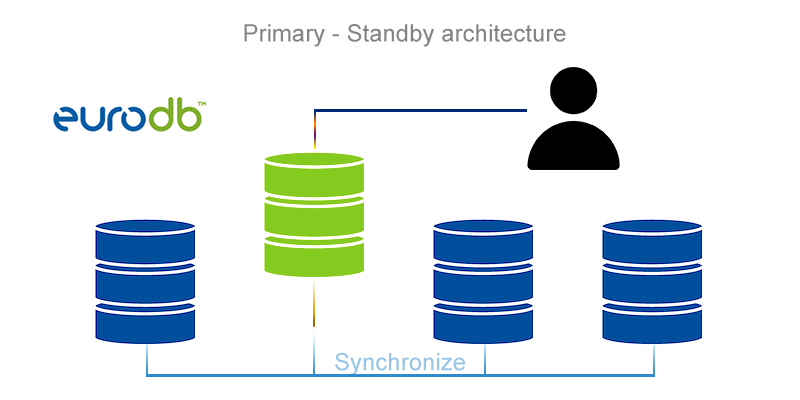
Primary-Standby
The Primary-Standby architecture is the most basic, and at the same time the easiest to implement and maintain form of the High Availability system. It features one main database called “Primary” and multiple “Standby” backup databases, which are constantly synchronised with the main database. Backup servers, having all possible information from the main database, can very quickly turn into a “Primary” database in the event of a failure. We distinguish two main types of “Standby” databases:
- logical – replication between “Primary” and “Standby” databases takes place only by copying the execution of SQL queries
- physical – replication between “Primary” and “Standby” databases is performed by sending information about database structure modifications.
To maintain maximum confidence in the synchronisation of the “Standby” database, PostgreSQL uses special WAL logs (write-ahead logs) that store all information about changes in the database.
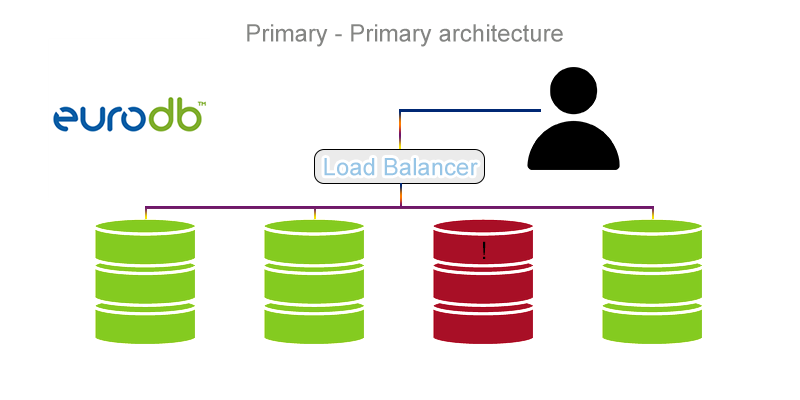
Primary-Primary
Unlike its predecessor, the Primary-Primary architecture does not have backup servers, but many “Primary” databases that can store and read data. By gently losing the speed of response, we gain reliability in operation, which is a reasonable settlement.
Unfortunately, this architecture is more complicated to create and requires learning what the “Load Balancing” is. It is a technology used to allocate the load to various elements of the system, for example databases. Applications that are used for this purpose not only manage the load on each of the databases, but also assign subsequent queries to a database if they detect its proper operation.
Failover in PostgreSQL
It should be remembered that by creating the right architecture alone we will not give the system High Availability status, because it meets only one rule of HA systems, i.e. “elimination of single points of failure”. The next step to creating a high availability system is to introduce a failover mechanism, which assumes that when a server or any element of the system fails, another takes over its role.
On the example of the Primary-Standby architecture, it would be a situation in which the “Primary” database fails, so one of the previously defined “Standby” databases is transformed into “Primary”, at the same time taking over its tasks. It should be noted that during the failure of one of the “Standby” servers, the failover mechanism is not started. This is because, without any additional interference, the system is still active and operational.
The failover mechanism is natively available on the EuroDB platform and works perfectly with other administration tools provided within this solution, which inform about the state of the system on an ongoing basis, as well as search logs for potential errors. The system, which is configured in such a way that it provides a failover mechanism and additionally informs administrators about its status, deserves to be called a system with high reliability.
Summary
A proven way to provide the company with an additional sense of security and trust among customers is to transform the system into a highly available system compliant with the rules. Benefits from the introduction of HA may not be visible at first glance. However, in the long run, some failures are bound to occur. Therefore, the only thing we can do is prepare for them in advance. When the time comes to repair a failure, specialists also feel more comfortable if the system is active and working all the time. There is also the awareness that the error occurs only on one of several available copies of the database.
Using EuroDB, whose central component is the PostgreSQL engine, we have the opportunity to use many tools to facilitate monitoring, administration, as well as the creation of a high availability system from the beginning. The prepared tools are ready to build a Primary-Standby architecture, along with access to the failover mechanism. Another advantage of having a EuroDB platform is the professional technical assistance provided by certified architects and engineers.