
 2020-07-20
2020-07-20
Proxy in PostgreSQL – load balancing and high-availability solutions
What are the benefits of database proxy? How does a proxy relate to high-availability solutions? Can a connection pooler offer any new possibilities? In this instalment of the series on creating reliable replicated PostgreSQL clusters, I will try to answer the above questions.
What are the benefits of database proxy? How does a proxy relate to high-availability solutions? Can a connection pooler offer any new possibilities? In this instalment of the series on creating reliable replicated PostgreSQL clusters, I will try to answer the above questions.
In previous articles we discussed the types of replication PostgreSQL has to offer and how we can monitor and manage replication using open source tooling. Today we will focus on the tools that fill a gap in the wide range of functionalities offered by Postgres, namely solutions situated between application and the database, most often used to provide connection pooling to the database, commonly known as poolers, and generally referred to as proxies.
Database connection pooler
PostgreSQL as a database engine does not manage a queue of connections to itself. It is quite natural that in order to tune the database configuration to the owned hardware, we can change the number of available connections (max_connections), but making changes to this parameter requires a database restart. This is directly related to the PostgreSQL architecture – a new process (backend in Postgres terms) is created for each open connection, which in turn is granted some exclusive resources (the main factor is the memory).
While performing the stress tests we can often see that increasing of the number of connections will yield better performance. Unfortunately, only up until a certain point, after which we start to lose again. In production deployments, one of the most important tasks of DBA is to determine the ideal number of connections for a given hardware configuration, and (even more so) for the type of workload associated with the application using the database. Knowing this parameter, we can improve the overall performance of the application. However, what about apps that are opening more connections than is reasonable, which causes errors like this:
error: could not connect to server: FATAL: sorry, too many clients already
When we control the application code, the best solution may be to roll out our own connection pooling (some frameworks or application servers do this by default), especially when we have the resources to do it and we want to perfectly tune the applications access patterns to the database. Often times, however, such a solution is costly (and may not yield much profit) or may simply be impossible (especially in the case of commercial out-of-the-box applications, where it is virtually impossible to change the code).
In this case, a natural solution to this problem is to tackle it architecturally by adding a database proxy, which will handle the surge of connections to the database without the need to reconfigure the database itself.
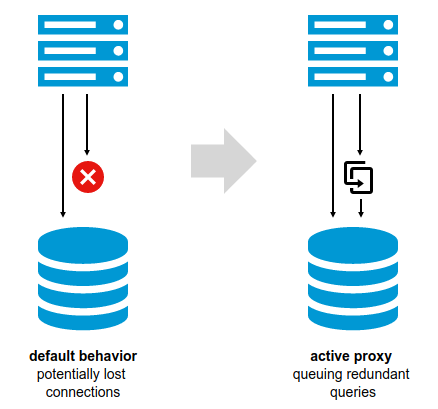
Depending on their intelligence, some of the available proxies allow much more than a simple solution to the above-mentioned problem. They hide, or rather abstract, the database layer from the application layer, allowing, for instance, to create high-availability database clusters. They can also increase application performance by balancing the load based on its type – e.g. by sending read-only queries to standby nodes. However, for this to work we need a smart proxy that is capable of decoding and interpreting the PostgreSQL application protocol in order to take appropriate actions.
PgBouncer a proxy for PostgreSQL
The pgBouncer is a good example of an open source database proxy. Thanks to the ability to interpret queries intended for Postgres, it allows the maintaining of a pool of connections on different levels, depending on the needs of our application:
- session level – the level that most resembles a regular database connection. The client uses one connection to the database at all times until the end of the session.
- transaction level – on this level individual transactions can be handled by different connections to the database, potentially allowing for better results. However, not all applications can use this method if they depend on PostgreSQL features available only at the session level.
- query level – the lowest available level, where each query would be treated as a separate transaction.
In the case of pgBouncer, one of the most interesting features it offers is the ability to reload the configuration on the fly, which allows you to create advanced architectures adapting to even the most demanding tasks.
Proxy in High-Availability environments
As we wrote in previous articles in the series, one of the problems encountered during a failure in a high-availability cluster is the need to tell the application the address of the new primary server. Yet, if the application communicates with a proxy (especially when we can’t change anything in it), we can move it to a layer in our direct control. In the case of pgBouncer, the possibility of dynamic reconfiguration is greatly aided by another feature, namely pausing the transfer of connections between proxy and the database and queuing them for some time.
This allows for a switchover of the primary database server to one of the standbys, which the application will perceive as a small delay in handling requests, but will allow the operations team to carry out routine maintenance work. The only requirement for the app is that is allow slower handling of the queries.
Summary
This concludes the series on building high-availability clusters for PostgreSQL and EuroDB. We deal with these and other similar issues by providing professional services for PostgreSQL and EuroDB for our clients. For more information please visit our contact page.